第13章 PE文件格式
本文最后更新于:2022年5月19日 晚上
本章将详细讲解Windows操作系统的PE(Portable Executable)文件格式相关知识。学习PE文件格式的过程中,也一起整理一下有关进程、内存、DLL等的内容,它们是Windows操作系统最核心的部分。
13.1 介绍
PE文件是Windows操作系统下使用的可执行文件格式。它是微软在UNIX平台的COFF(Common Object File Format,通用对象文件格式)基础上制作而成的。最初(正如Portable这个单词所代表的那样)设计用来提高程序在不同操作系统上的移植性,但实际上这种文件格式仅用在Windows系列的操作系统下。
PE文件是指32位的可执行文件,也称为PE32。64位的可执行文件称为PE+或PE32+,是PE(PE32)文件的一种扩展形式(请注意不是PE64 )。
13.2 PE文件格式
PE文件种类如下表所示。
| 种类 | 主拓展名 |
|---|---|
| 可执行系列 | EXE、SCR |
| 库系列 | DLL、OCX、CPL、DRV |
| 驱动程序系列 | SYS、VXD |
| 对象文件系列 | OBJ |
严格地说,OBJ (对象)文件之外的所有文件都是可执行的。DLL、SYS文件等虽然不能直接在Shell (Explorer.exe)中运行,但可以使用其他方法(调试器、服务等)执行。
根据PE正式规范,编译结果OBJ文件也视为PE文件。但是OBJ文件本身不能以任何形式执行,在代码逆向分析中几乎不需要关注它。
下面以记事本(notepad.exe)程序进行简单说明,首先使用Hex Editor打开记事本程序。
下图是notepad.exe文件的起始部分,也是PE文件的头部分(PE header)。notepad.exe文件运行需要的所有信息就存储在这个PE头中。如何加载到内存、从何处开始运行、运行中需要的DLL有哪些、需要多大的栈/堆内存等,大量信息以结构体形式存储在PE头中。换言之,学习PE文件格式就是学习PE头中的结构体。
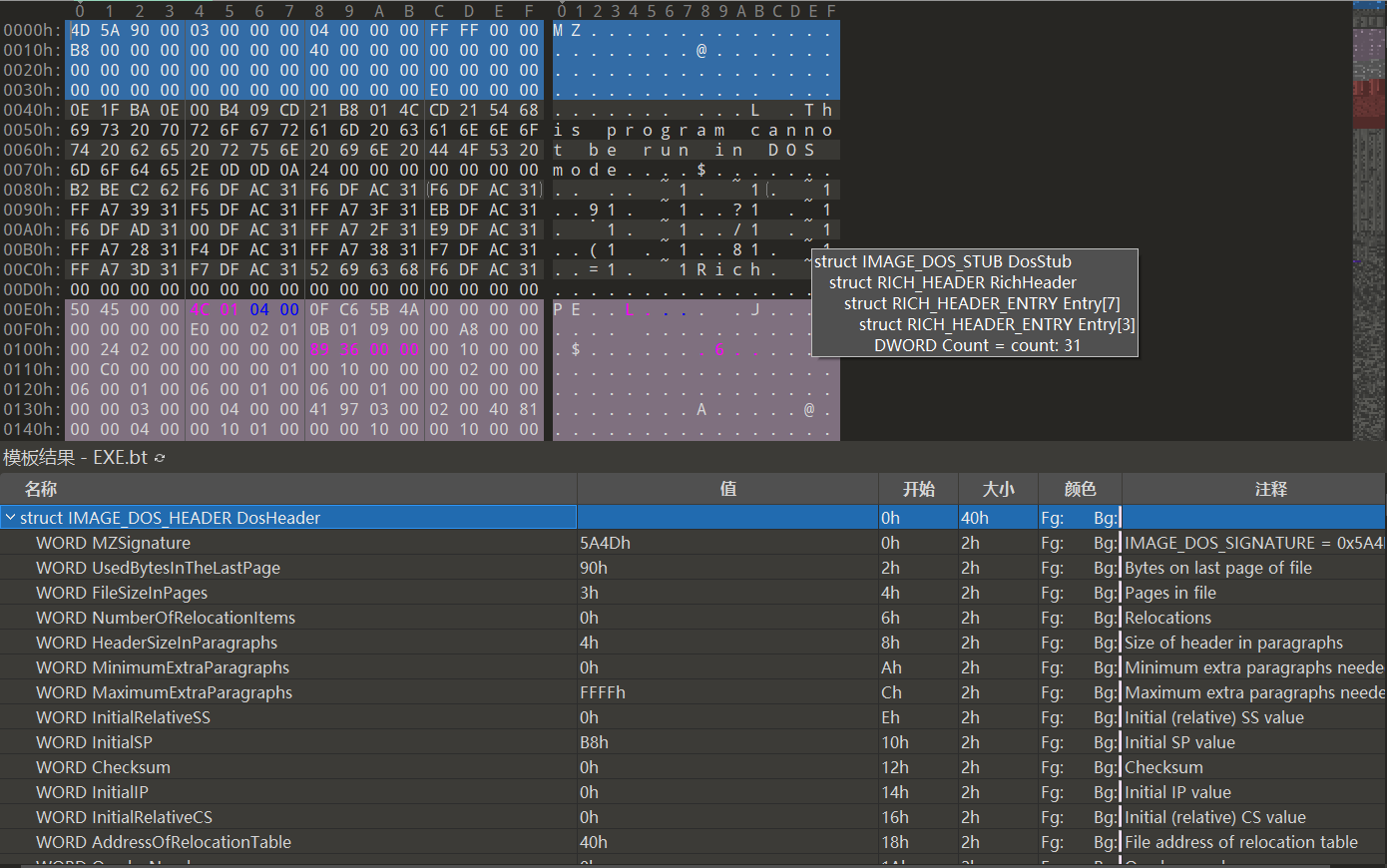
书中将以Windows XP SP3的notepad.exe为例进行说明,与其他版本Windows下 的notepad.exe文件结构类似,但是地址不同。在我的随书实验过程中,我使用的是32位win7的文件夹底下的notepad进行实验。
13.2.1 基本结构
notepad.exe具有普通PE文件的基本结构。下图描述了notepad.exe文件加载到内存时的情形。
其中包含了许多内容,下面逐一学习。
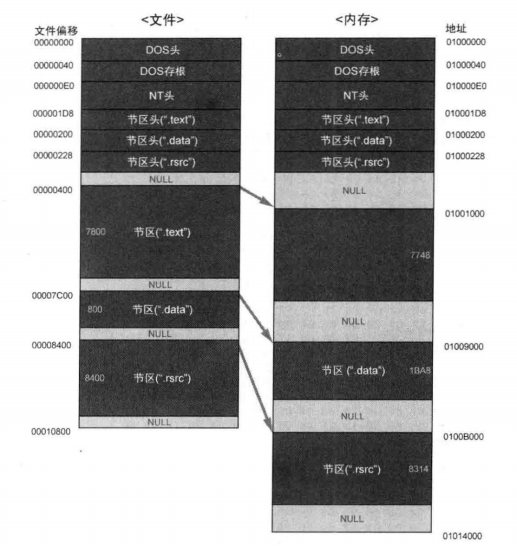
从DOS头(DOS header)到节区头(Section header)是PE头部分,其下的节区合称PE体。文件中使用偏移(offset),内存中使用VA (Virtual Address,虚拟地址)来表示位置。文件加载到内存时,情况就会发生变化(节区的大小、位置等)。文件的内容一般可分为代码(.text)、数据(.data )、资源(.rsrc )节,分别保存。
根据所用的不同开发工具(VB/VC++/Delphi/etc)与编译选项,节区的名称、大小、
个数、存储的内容等都是不同的。最重要的是它们按照不同的用途分类保存到不同的节中。
各节区头定义了各节区在文件或内存中的大小、位置、属性等。
PE头与各节区的尾部存在一个区域,称为NULL填充(NULL padding)。计算机中,为了提高处理文件、内存、网络包的效率,使用“最小基本单位”这一概念,PE文件中也类似。文件/内存中节区的起始位置应该在各文件/内存最小单位的倍数位置上,空白区域将用NULL填充(看上图,可以看到各节区起始地址的截断都遵循一定规则)。
13.2.2 VA&RVA&FOA(RAW)
VA指的是进程虚拟内存的绝对地址,RVA ( Relative Virtual Address,相对虚拟地址)指从某个基准位置(ImageBase )开始的相对地址。
VA与RVA满足的换算关系为RVA+ImageBase=VA
PE头内部信息大多以RVA形式存在。原因在于,PE文件(主要是DLL)加载到进程虚拟内存的特定位置时,该位置可能已经加载了其他PE文件(DLL )。此时必须通过重定位(Relocation )将其加载到其他空白的位置,若PE头信息使用的是VA,则无法正常访问。因此使用RVA来定位信息,即使发生了重定位,只要相对于基准位置的相对地址没有变化,就能正常访问到指定信息,不会出现任何问题
至于FOV的话就比较简单,它是文件中的偏移地址
32位Windows OS中,各进程分配有4GB的虚拟内存,因此进程中VA值的范围是00000000〜FFFFFFFF。
13.3 PE头
PE头由许多结构体组成,现在开始逐一学习各结构体。此外还会详细讲解在代码逆向分析中起着重要作用的结构体成员。
13.3.1 DOS 头
微软创建PE文件格式时,入们正广泛使用DOS文件,所以微软充分考虑了PE文件对DOS文件的兼容性。其结果是在PE头的最前面添加了一个IMAGE_DOS_HEADER结构体,用来扩展已有的DOS EXE头。
1 | |
自实现代码解析
IMAGE_DOS_HEADER结构体的大小为40个字节。在其中最重要的两个字段如下:
e_magic:一个WORD类型,值是一个常数0x4D5A,用文本编辑器查看该值位‘MZ’,可执行文件必须都是’MZ’开头。
e_lfanew:为32位可执行文件扩展的域,用来表示DOS头之后的NT头相对文件起始地址的偏移。
使用Hex Editor打开notepad.exe,查看IMAGE_DOS_HEADERS结构体,可以看上面打开的图。根据PE规范,文件开始的2个字节为4D5A,e_lfanew值为000000E0(不是E0000000)。
Intel系列的CPU以逆序存储数据,这称为小端序标识法。
自己写代码可以加深对PE头的理解,接下来手写代码解析MS-DOS头:
1 | |
13.3.2 DOS存根
DOS存根(stub)在DOS头下方,是个可选项,且大小不固定(即使没有DOS存根,文件也能正常运行)。DOS存根由代码与数据混合而成,下图显示的就是notepad.exe的DOS存根。
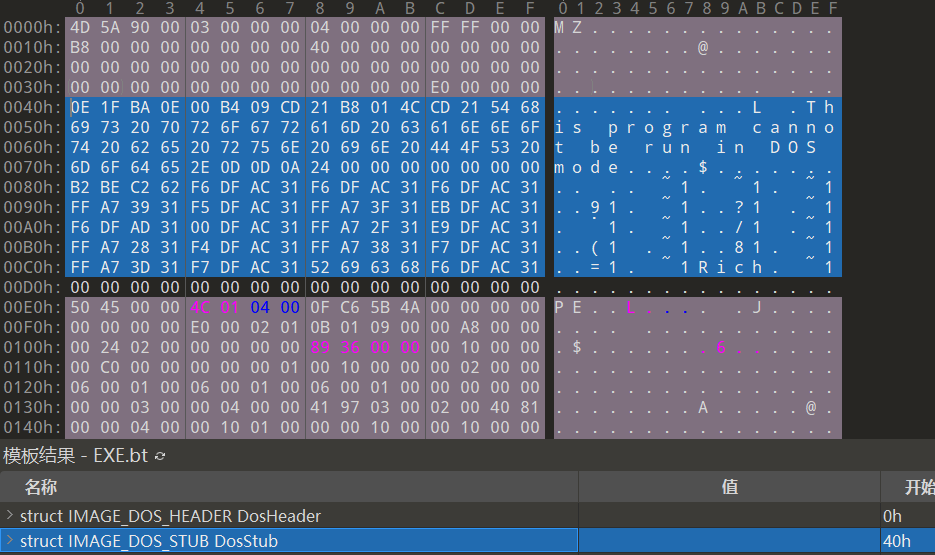
上图中,文件偏移40~4D区域为16位的汇编指令。32位的Windows OS中不会运行该命令(由于被识别为PE文件,所以完全忽视该代码)。在DOS环境中运行Notepad.exe文件,或者使用DOS调试器(debug.exe)运行它,可使其执行该代码(不认识PE文件格式,所以被识别为DOS EXE文件)。
打开命令行窗口(cmd.exe),输入如下命令(仅适用于Windows XP环境)。
debug C:\Windows\notepad.exe
在出现的光标位置上输入“u”指令(Unassemble),将会岀现16位的汇编指令,如下所示。
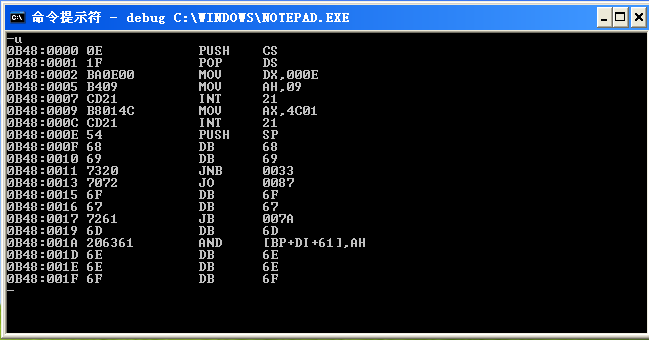
对汇编代码的解释参考书:

代码非常简单,在画面中输岀字符串“This program cannot be run in DOS mode”后就退出。
换言之,notepad.exe文件虽然是32位的PE文件,但是带有MS-DOS兼容模式,可以在DOS环境中运行,执行DOS EXE代码,输出“This program cannot be run in DOS mode”后终止。灵活使用该特性可以在一个可执行文件(EXE)中创建岀另一个文件,它在DOS与Windows中都能运行(在DOS环境中运行16位DOS代码,在Windows环境中运行32位Windows代码)。
如前所述,DOS存根是可选项,开发工具应该支持它(VB、VC++、Delphi等默认支持DOS存根)
13.3.3 NT头
NT头结构体如下:
1 | |
IMAGE_NT_HEADERS结构体由3个成员组成,第一个成员为签名(Signature )结构体,其值为50450000h( “PE” 00 )。另外两个成员分别为文件头(File Header)与可选头( Optional Header)结构体。使用Hex Editor打开notepad.exe,查看IMAGE_NT_HEADERS,如下图所示。
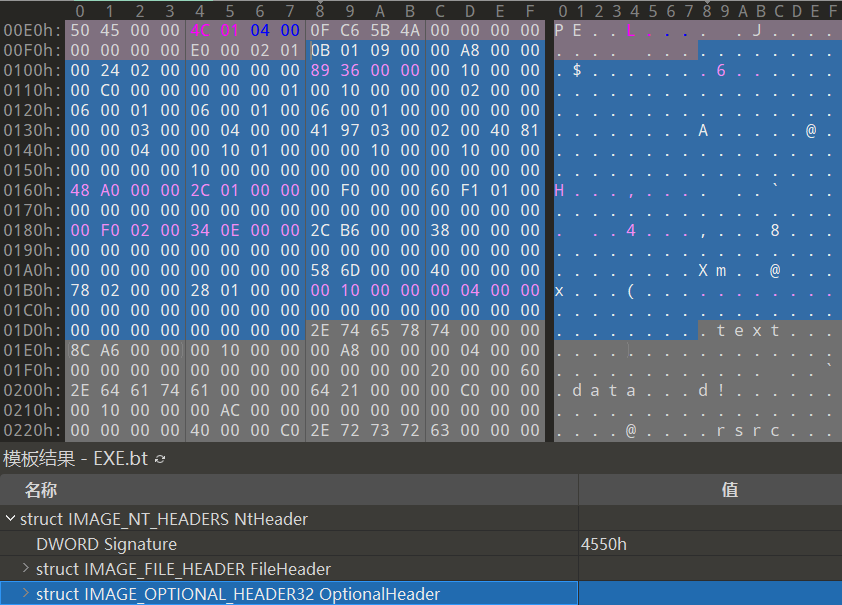
IMAGE_NT_HEADERS结构体的大小为F8,相当大。下面分别讲解文件头与可选头结构体。
13.3.4 NT头:文件头
IMAGE_FILE_HEADER
文件头是表现文件大致属性的结构体。
1 | |
IMAGE_FILE_HEADERS结构体中有如下4种重要成员(若它们设置不正确,将导致文件无法正常运行)。
Machine
每个CPU都拥有唯一的Machine码,兼容32位Intel x86芯片的Machine码为14C。以下是定义在winnt.h文件中的Machine码。
1 | |
NumberOfSections
前面提到过,PE文件把代码、数据、资源等依据属性分类到各节区中存储。
NumberOfSections用来指出文件中存在的节区数量。该值一定要大于0,且当定义的节区数量与实际节区不同时,将发生运行错误。
TimeDateStamp
该PE文件生成的时间。该成员的值不影响文件运行,用 来记录编译器创建此文件的时间。但是有些开发工具(VB、VC++)提供了设置该值的工具,而有些开发工具(Delphi)则未提供(且随所用选项的不同而不同)。
PointerToSymbolTable
这个已经逐渐弃用了,这里不再介绍。
NumberOfSymbols
这个已经逐渐弃用了,这里不再介绍。
SizeOfOptionalHeader
IMAGE_NT_HEADER结构体的最后一个成员为IMAGE_OPTIONAL_HEADER32结构体。SizeOfOptionalHeader成员用来指岀 IMAGE_OPTIONAL_HEADER32结构体的长度。IMAGE_OPTIONAL_HJEADER32结构体由C语言编写而成,故其大小已经确定。但是Windows的PE装载器需要查看IMAGE_FILE_HEADER的SizeOfOptionalHeader值,从而识别出MAGE_OPTIONAL_HEADER32结构体的大小。
PE32+格式的文件中使用的是IMAGE_OPTIONAL_HEADER64结构体,而不是IMAGE_OPTIONAL_HEADER32结构体。2个结构体的尺寸是不同的,所以需要在SizeOfOptionaUieader成员中明确指出结构体的大小。
借助 IMAGE_DOS_HEADER 的 ejfanew 成员与 IMAGE_FILE_HEADER 的SizeOfOptionalHeader成员,可以创建出一种脱离常规的PE文件(PE Patch )(也有入称之为“麻花” PE文件)。
Characteristics
该字段用于标识文件的属性,文件是否是可运行的形态、是否为DLL文件等信息,以bit OR形式组合起来。以下是定义在winnt.h文件中的(请记住0002h与2000h这两个值)。
1 | |
另外,PE文件中Characteristics的值有可能不是0002h吗(不可执行)?是的,确实存在这种情况。比如类似*.obj的object文件及resource DLL文件等。
自实现代码解析
编写如下代码对PE文件的FileHeader进行分析:
1 | |
13.3.5 NT头:可选头
表面上有的头是Optional的,实际上它是最大也是最为重要的一个PE结构。
1 | |
在IMAGE_OPTIONAL_HEADER32结构体中需要关注下列成员。这些值是文件运行必需的,设置错误将导致文件无法正常运行。
Magic
为IMAGE_OPTIONAL_HEADER32结构体时,Magic码为 10B ;为 IMAGE_OPTIONAL_HEADER64结构体时,Magic码为20B。AddressOfEntryPoint
AddressOffEntryPoint持有EP的RVA值。该值指出程序最先执行的代码起始地址,相当重要。ImageBase
进程虚拟内存的范围是0〜FFFFFFFF (32位系统)。PE文件被加载到如此大的内存中时,ImageBase指出文件的优先装入地址。EXE、DLL文件被装载到用户内存的0〜7FFFFFFF中,SYS文件被载入内核内存的80000000〜FFFFFFFF中。一般而言,使用开发工具(VB/VO+/Delphi)创建好EXE文件后,其ImageBase的值为00400000, DLL文件的ImageBase值为10000000 (当然也可以指定为其他值)。执行PE文件时,PE装载器先创建进程,再将文件载入内存,然后把EIP寄存器的值设置为ImageBase+AddressOfEntryPoint。SectionAlignment,FileAlignment
PE文件的Body部分划分为若干节区,这些节存储着不同类别的数据。FileAlignment指定了节区在磁盘文件中的最小单位,而SectionAlignment则指定了节区在内存中的最小单位(一个文件中,FileAlignment与SectionAlignment的值可能相同,也可能不同)。磁盘文件或内存的节区大小必定为FileAlignment或SectionAlignment值的整数倍。SizeOfImage
加载PE文件到内存时,SizeOfImage指定了PE Image在虚拟内存中所#占空间的大小。一般而言,文件的大小与加载到内存中的大小是不同的(节区头中定义了各节装载的位置与占有内存的大小,后面会讲到)。SizeOfHeader
SizeOfHeader用来指出整个PE头的大小。该值也必须是FileAlignment的整数倍。第一节区所在位置与SizeOfHeader距文件开始偏移的量相同。Subsystem
该Subsystem值用来区分系统驱动文件(*.sys )与普通的可执行文件(*.exe, *.dll)。 Subsystem成员可拥有的值如表13-2所示(部分)。
1 | |
NumberOfRvaAndSizes
NumberOfRvaAndSizes 用来指定DataDirectory(IMAGE_OPTIONAL_HEADER32结构体的最后一个成员)数组的个数。虽然结构体定义中明确指出了数组个数为IMAGE_NUMBEROF_DIRECTORY_ENTRIES(16),但是PE装载器通过查看NumberOfRvaAndSizes值来识别数组大小,换言之,数组大小也可能不是16。DataDirectory
DataDirectory是由IMAGE_DATA_DIRECTORY结构体组成的数组,数组的每项都有被定义的值。如下列出了各数组项
1 | |
如下是notepad.exe的IMAGE_OPTIONAL_HEADER结构体。
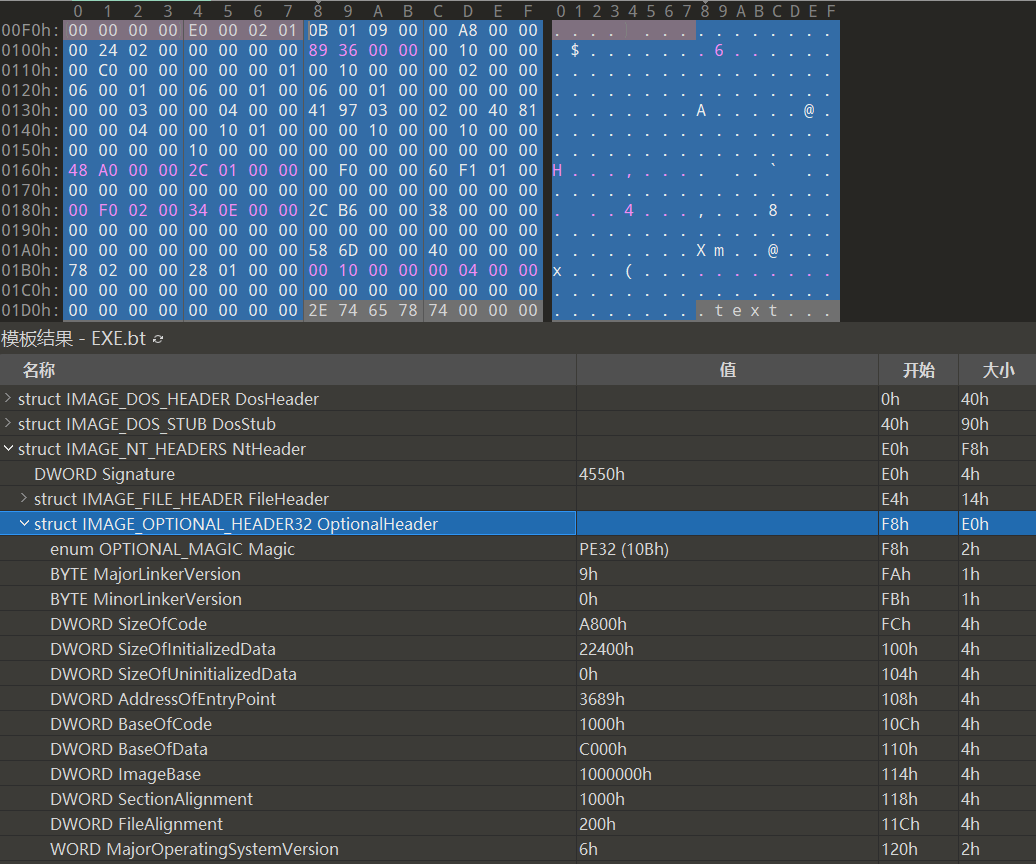
13.3.6 节区头
节区头中定义了各节区属性。看节区头之前先思考一下:前面提到过,PE文件中的code (代码)、data (数据)、resource (资源)等按照属性分类存储在不同节区,设计PE文件格式的工程师们之所以这样做,一定有着某些好处。
我认为把PE文件创建成多个节区结构的好处是,这样可以保证程序的安全性。若把code与data放在一个节区中相互纠缠(实际上完全可以这样做)很容易引发安全问题,即使忽略过程的烦琐。
假如向字符串data写数据时,由于某个原因导致溢出(输入超过缓冲区大小时),那么其下的code (指令)就会被覆盖,应用程序就会崩溃。因此,PE文件格式的设计者们决定把具有相似属性的数据统一保存在一个被称为“节区”的地方,然后需要把各节区属性记录在节区头中(节区属性中有文件/内存的起始位置、大小、访问权限等)。
换言之,需要为每个code/data/resource分别设置不同的特性、访问权限等,如下表。
| 节名 | 作用 |
|---|---|
| . text/.code | .exe或DLL文件的代码 |
| . data | 已经初始化的数据 |
| . edata | 输出文件名表 |
| . idata | 输入文件名表 |
| . rdata | 运行期只读数据 |
| . reloc | 重定位表信息 |
| . rsrc | 资源 |
| . bss | 未经初始化的数据 |
| . crt | C运行期只读数据 |
| . debug | 调试信息 |
| . didata | 延迟输入文件名表 |
| . tls | 线程的本地存储器 |
| . xdata | 异常处理表 |
至此,大家应当对节区头的作用有了大致了解。
IMAGE_SECTION_HEADER
节区头是由IMAGE_SECTION_HEADER结构体组成的数组,每个结构体对应一个节区。下面代码给出节区头的结构体定义。
1 | |
这里需要说明的是,VirtualAddress与PointerToRawData不带有任何值,分别由(定义在IMAGE_OPTIONAL_HEADER32中的)SectionAlignment与FileAlignment确定。
VirtualSize与SizeOfRawData—般具有不同的值,即磁盘文件中节区的大小与加载到内存中的节区大小是不同的。
Characteristics由下面代码中中显示的值组合(bit OR)而成。这里只展示了部分重要的节区属性。
1 | |
最后谈谈Name字段。Name成员不像C语言中的字符串一样以NULL结束,并且没有“必须使用ASCII值”的限制。PE规范未明确规定节区的Name,所以可以向其中放入任何值,甚至可以填充NULL值。所以节区的Name仅供参考,不能保证其百分之百地被用作某种信息(数据节区的名称也可叫做.code )。
讲解PE文件时经常出现“映像”(Image)这一术语,希望各位牢记。PE文件加 栽到内存时,文件不会原封不动地加载,而要根据节区头中定义的节区起始地址、节区大小等加载。因此,磁盘文件中的PE与内存中的PE具有不同形态。将装载到内存中的形态称为“映像”以示区别,使用这一术语能够很好地区分二者
自实现代码解析
编写如下代码可以帮助我们分析节表:
1 | |
其中IMAGE_FIRST_SECTION是内置的宏定义,摘抄如下:
1 | |
13.4 RVAtoRAW
理解了节区头后,下面继续讲解有关PE文件从磁盘到内存映射的内容。PE文件加载到内存时,每个节区都要能准确完成内存地址与文件偏移间的映射。这种映射一般称为RVA to RAW,方法如下。
(1)查找RVA所在节区。
(2)使用简单的公式计算文件偏移(RAW)。根据IMAGE_SECTION_HEADER结构体,换算公式如下:
RAW - PointerToRawData = RVA - VirtualAddress
RAW = RVA - VirtualAddress + PointerToRawData
为了便于说明,给出之前的notepad.exe在磁盘中和在内存中的拉伸对比图:
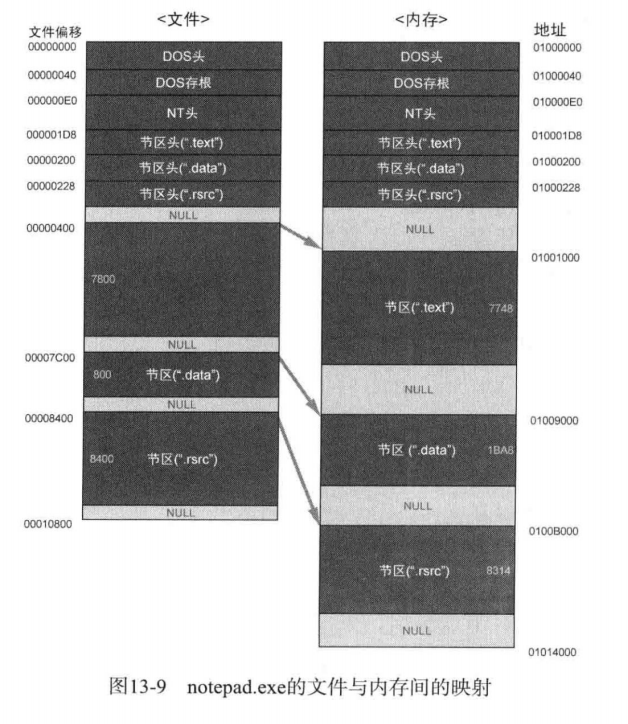
这里补充一些东西,一方面我们可以看到这个文件中节区的大小和内存中的是不一样的。这是因为磁盘文件对齐的字节数和内存中的不一样。这里大概可以看出磁盘中对齐字节数是100h,而内存中是4h。
另一方面就是书上的Quiz3,题目、答案与解释如下:

像Q3—样,PE文件节区中因VirtualSize与SizeOfRawData值彼此不同而引起的奇怪、有趣的事还有很多(后面会陆续讲到)。
RVA与RAW (文件偏移)间的相互变换是PE头的最基本的内容,各位一定要熟悉并掌握它们之间的转换关系。
自实现代码解析
我们也可以根据如上方法论编写地址转换函数,从代码也不难看出此代码也存在Q3类似的问题。
1 | |
13.5 IAT
刚开始学习PE头时,最难过的一关就是IAT (Import Address Table,导入地址表)。IAT保存的内容与Windows操作系统的核心进程、内存、DLL结构等有关。换句话说,只要理解了IAT,就掌握了Windows操作系统的根基。简言之,IAT是一种表格,用来记录程序正在使用哪些库中的哪些函数。
13.5.1 DLL
讲解IAT前先学习一下有关DLL ( Dynamic Linked Library )的知识(知其所以然,才更易理解),它支撑起了整座Windows OS大厦。DLL翻译成中文为“动态链接库”,为何这样称呼呢?16位的DOS时代不存在DLL这一概念,只有“库”(Library )—说。比如在C语言中使用printf()函数时,编译器会先从C库中读取相应函数的二进制代码,然后插入(包含到)应用程序。也就是说,可执行文件中包含着printf()函数的二进制代码。Windows OS支持多任务,若仍采用这种包含库的方式,会非常没有效率。Windows操作系统使用了数量庞大的库函数(进程、内存、窗口、消息等)来支持32位的Windows环境。同时运行多个程序时,若仍像以前一样每个程序运行时都包含相同的库,将造成严重的内存浪费(当然磁盘空间的浪费也不容小觑)。因此,WindowsOS设计者们根据需要引入了DLL这一概念,描述如下。
- 不要把库包含到程序中,单独组成DLL文件,需要时调用即可。
- 内存映射技术使加载后的DLL代码、资源在多个进程中实现共享。
- 更新库时只要替换相关DLL文件即可,简便易行。加载DLL的方式实际有两种:一种是“显式链接”(ExplicitLinking),程序使用DLL时加载,使用完毕后释放内存;另一种是“隐式链接” (Implicit Linking ),程序开始时即一同加载DLL,程序终止时再释放占用的内存。IAT提供的机制即与隐式链接有关。下面使用OllyDbg打开notepad.exe来查看IAT。图13-10是调用CreateFileW()函数的代码,该函数位于kernel32.dll中。
调用CreateFileW()函数时并非直接调用,而是通过获取01001104地址处的值来实现(所有API调用均采用这种方式)。地址01001104是notepad.exe中.text节区的内存区域(更确切地说是IAT内存区域)。01001104地址的值为7C8107F0,而7C8107F0地址即是加载到notepad.exe进程内存中的CreateFileW()函数(位于kernel32.dll库中)的地址。
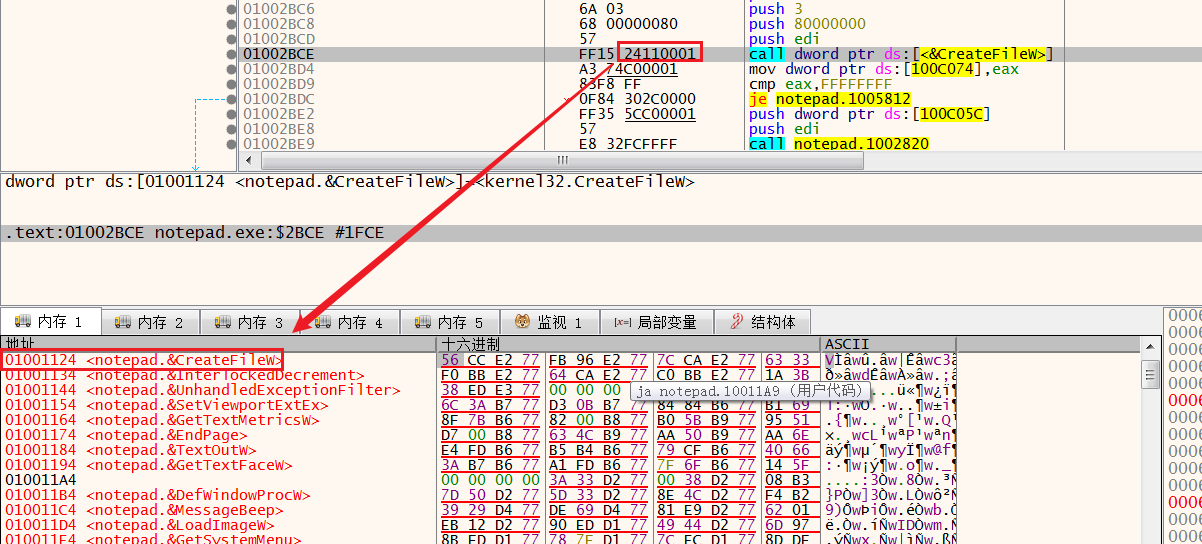
此处产生一个疑问。
“直接使用CALL 7C8107F0指令调用函数不是更好、更方便吗?”
甚至还会有入问:“编译器直接写CALL 77E2CC56不是更准确、更好吗?”这是前面说过的DOS时代的方式。事实上,notepad.exe程序的制作者编译(生成)程序时,并不知道该notepad.exe程序要运行在哪种Windows ( 9X、2K、XP、Vista、7 )、哪种语言(ENG、JPN、KOR等)、哪种服务包(ServicePack)下。上面列举出的所有环境中,kernel32.dll的版本各不相同,CreateFileW()函数的位置(地 址)也不相同。为了确保在所有环境中都能正常调用CreateFileW()函数,编译器准备了要保存CreateFileW()函数实际地址的位置( 10001124),并仅记下CALL DWORD PTR DS:[10001124]形式的指令。执行文件时,PE装载器将CreateFileWO函数的地址写到10001124位置。
编译器不使用CALL 77E2CC56语句的另一个原因在于DLL重定位。DLL文件的ImageBase值一般为10000000。比如某个程序使用a.dll与b.dll时,PE装载器先把a.dll装载到内存的10000000(ImageBase)处,然后尝试把b.dll也装载到该处。但是由于该地址处已经装载了a.dll,所以PE装载器查找其他空白的内存空间(ex:3E000000 ),然后将b.dll装载进去。
这就是所谓的DLL重定位,它使我们无法对实际地址硬编码。另一个原因在于,PE头中表示地址时不使用VA,而是RVA。
实际操作中无法保证DLL —定会被加载到PE头内指定的ImageBase处。但是EXE文件(生成进程的主体)却能准确加载到自身的ImageBase中,因为它拥有自己的虚拟空间。
PE头的IAT是代码逆向分析的核心内容。希望各位好好理解它。相信大家现在已经能够掌握IAT的作用了(后面讲解IAT结构为什么如此复杂时,希望各位也能很快了解)。
13.5.2 IMAGE_IMPORT_DESCRIPTOR
1 | |
执行一个普通程序时往往需要导入多个库,导入多少库就存在多少个IMAGE_IMPORT_DESCRIPTOR结构体,这些结构体形成了数组,且结构体数组最后以NULL结构体结束。IMAGE_IMPORT_DESCRIPTOR中的重要成员如表13-5所示(拥有全部RVA值)。
其中的重要成员如下所示:
- OriginalFirstThunk:INT的地址(RVA)
- Name:库名称字符串的地址(RVA)
- FirstThunk:IAT的地址(RVA)
• PE头中提到的“Table”即指数组。
• INT与IAT是长整型(4个字节数据类型)数组,以NULL结束(未另外明确指出
大小)。
• INT中各元素的值为IMAGE_IMPORT_BY_NAME结构体指针(有时IAT也拥有
相同的值)。
• INT与IAT的大小应相同。
下图描述了notepad.exe之kernel32.dll的IMAGE_IMPORT_DESCRIPTOR结构。
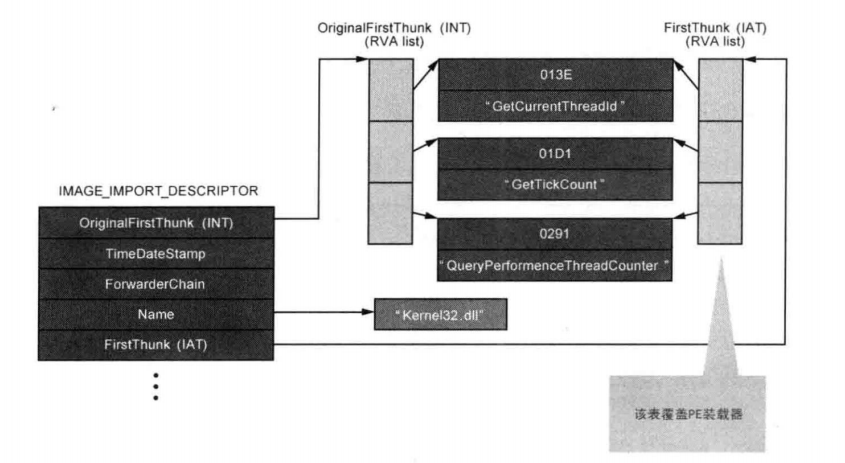
上图中,INT与IAT的各元素同时指向相同地址,但也有很多情况下它们是不一致的(后面会陆续接触很多变形的PE文件,到时再逐一讲解)。但至少在我们的notepad分析中,这两者是一致的。
下面了解一下PE装载器把导入函数输入至IAT的顺序。
- 1.读取IID的Name成员,获取库名称字符串kernel32.dll)。
- 2.装载相应库。
- LoadLibrary(“kernel32.dll”)
- 3.读取IID的OriginalFirstThunk成员,获取INT地址。
- 4.逐一读取INT中数组的值,获取相应IMAGE_IMPORT_BY_NAME地址(RVA)。
- 5.使用IMAGE_IMPORT_BY_NAME的Hint (ordinal)或fame项,获取相应函数的起始地址。
- GetProcAddress(“GetCurrentThreadld”)
- 6.读取IID的FirstThunk (IAT)成员.获得IAT地址。
- 7.将上面获得的函数地址输入相应IAT数组值。
- 8.重复以上步骤4~7,直到INT结束(遇到NULL时)。
13.5.3 notepad分析
下面以notepad.exe为对象逐一查看。先提一个问题:IMAGE_IMPORT_DESCRIPTOR结构体数组究竟存在于PE文件的哪个部分呢?
它不在PE头而在PE体中(在.idata段里),但查找其位置的信息在PE头中,IMAGE_OPTIONAL_HEADER32.DataDirectory[1].VirtualAddress的值即是IMAGE_IMPORT_DESCRIPTOR结构体数组的起始地址(RVA值)。IMAGE_IMPORT_DESCRIPTOR结构体数组也被称为IMPORT Directory Table (只有了解上述全部称谓,与他入交流时才能没有障碍)。
使用010editor对文件进行查看,找到导入表的RVA地址。
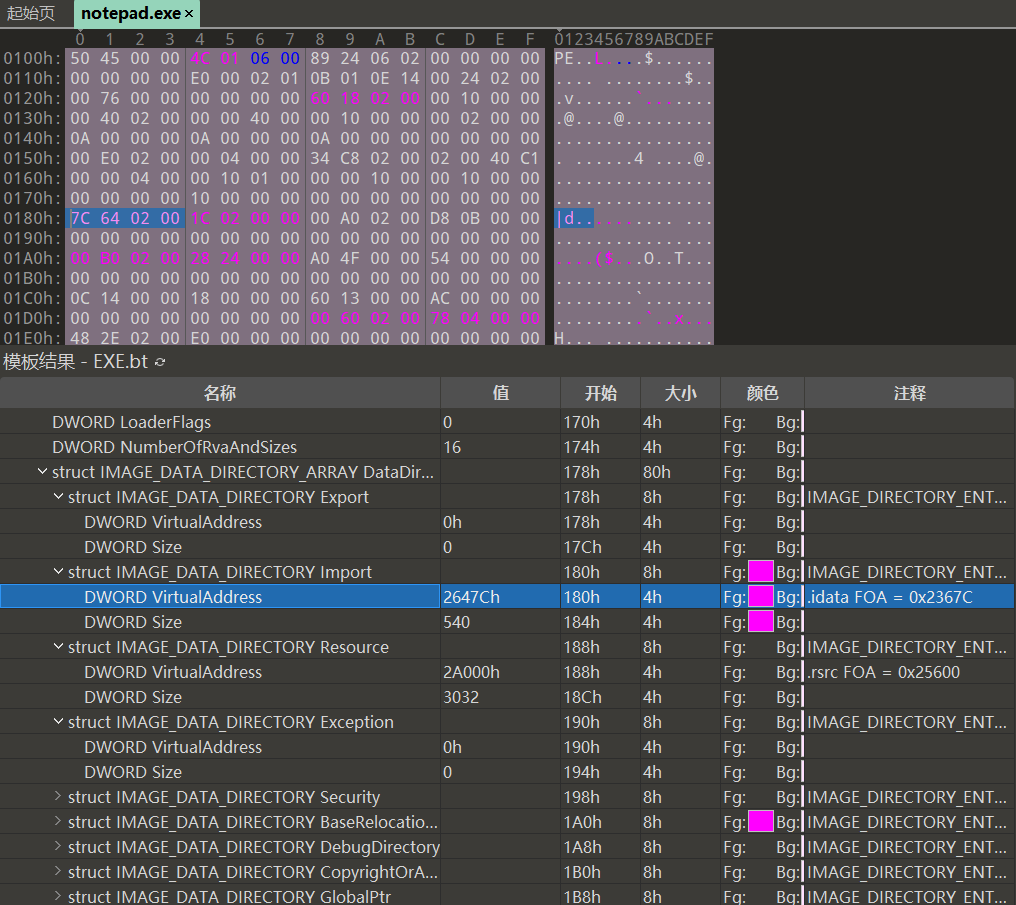
使用之前提到的RVAtoFOA函数对地址进行转换,找到导入表实际位置在文件中的偏移起始地址为2367C。由该地址开始引出一条的链,该链上的每一个块对应着一个DLL和通过这个DLL导入的一堆函数,以及一个IMAGE_IMPORT_DESCRIPTOR结构体。
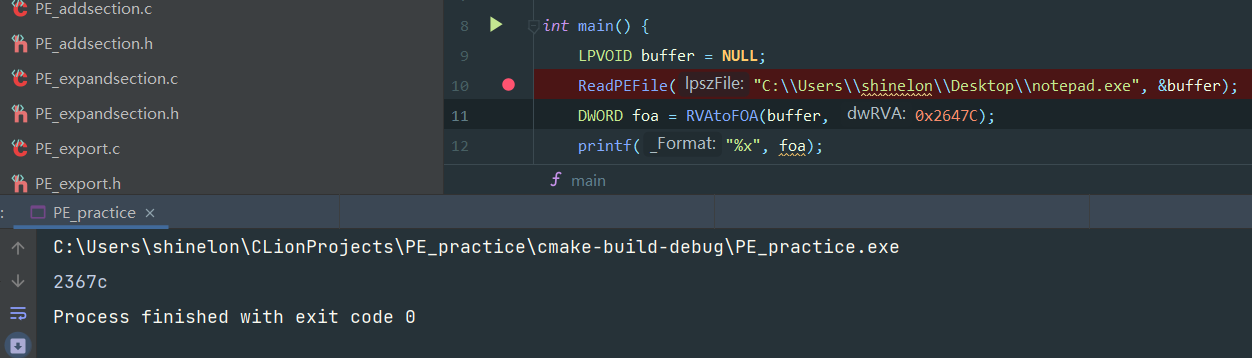
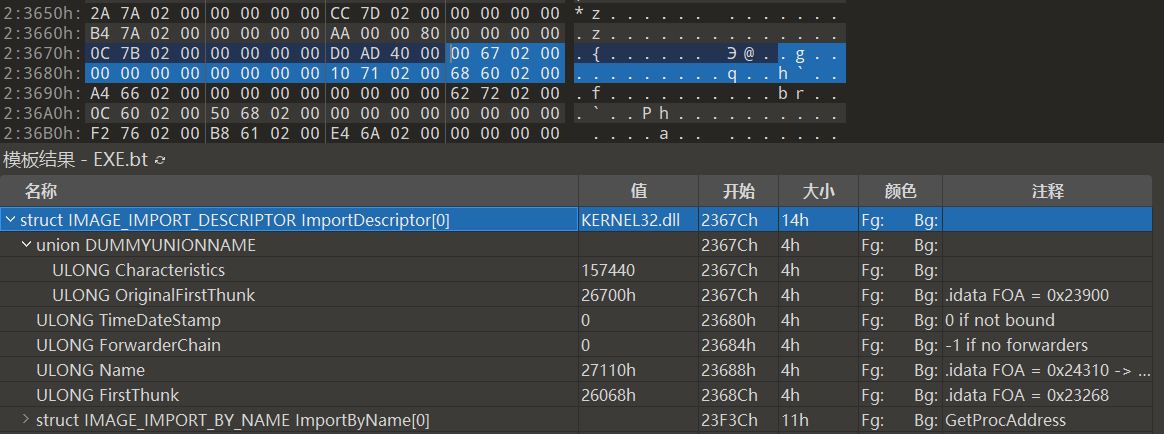
1 | |
将几个成员的值提取如下:
| 文件偏移 | 成员 | RVA | FOA(RAW) |
|---|---|---|---|
| 367C | OriginalFirstThunk(INT) | 26700 | 23900 |
| 3680 | TimeDateStamp | 0 | - |
| 3684 | ForwarderChain | 0 | - |
| 3688 | Name | 27110 | 24310 |
| 368C | FirstThunk(IAT) | 26068 | 23268 |
依此看看下面的这些文件吧。
- 库名称(Name)
Name是一个字符串指针,它指向导入函数所属的库文件名称。在下图文件偏移24310(RVA:27110→RAW:24310)处看到字符串KERNEL32.dll了吧?

- OriginalFirstThunk - INT
INT是一个包含导入函数信息(Ordinal, Name)的结构体指针数组。只有获得了这些信息,才能在加载到进程内存的库中准确求得相应函数的起始地址(请参考后面EAT的讲解)。
跟踪OriginalFirstThunk成员(RVA:26700→RAW:23900)。 结果如下。
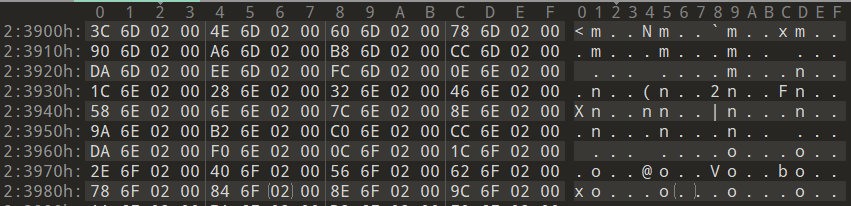
上图实际上就是INT,它由地址数组形式组成(数组尾部以NULL结束)。该地址数组实际上也有一个结构体IMAGE_THUNK_DATA来指代。这里我们使用的是AddressOfData的变量。
1 | |
需要说明的是,当 IMAGE_THUNK_DATA 值的最高位为 1时,表示函数以序号方式导入,这时候低 31位被看作一个函数序号。(可以用预定义值IMAGE_ORDINAL_FLAG32或80000000h来对最高位进行测试)。
当 IMAGE_THUNK_DATA 值的最高位为 0时,表示函数以字符串类型的函数名方式导入,这时双字的值是一个 RVA,指向一IMAGE_IMPORT_BY_NAME 结构。
而其中,每个地址值分别指向IMAGE_IMPORT_BY_NAME结构体。
1 | |
跟踪数组的第一个值26D3C(RVA),其FOA为23F3C:

进入该地址,可以看到导入的API函数的名称字符串。文件偏移23F3C最初的2个字节值(02B0)为Ordinal,在上述结构体中即为那个WORD变量,它是库中函数的固有编号。
Ordinal的后面 为函数名称字符串GetProcAddress(同C语言一样,字符串末尾以Terminating NULL[‘\0’ ]结束)。

可以看下之前放的图,对理解有帮助,如下:
- FirstThunk - IAT (Import Address Table)
IAT的RVA:26068即为RAW:23268
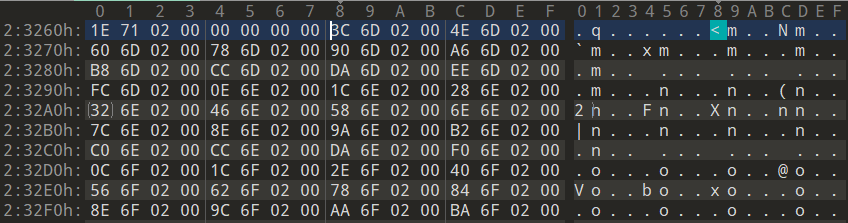
图13-17中文件偏移23268~234C0区域即为IAT数组区域,对应于kernel32.dll库。它与INT类似,由结构体指针数组组成,且以NULL结尾。
IAT的第一个元素值被硬编码为26D3C,该值无实际意义,notepad.exe文件加载到内存时,PE装载器会使用相应API的起始地址替换该值。替换后的值是准确的。
微软在制作服务包过程中重建相关系统文件,此时会硬编入准确地址(普通的 DLL实际地址不会被硬编码到IAT中,通常带有与INT相同的值)。
另外,普通DLL文件的ImageBase为10000000,所以经常会发生DLL重定位。但是Windows系统DLL文件(kernel32/user32/gdi32等)拥有自身固有的ImageBase,不会出现DLL重定位。
下面使用x32dbg查看notepad.exe的IAT,如图13-18所示。
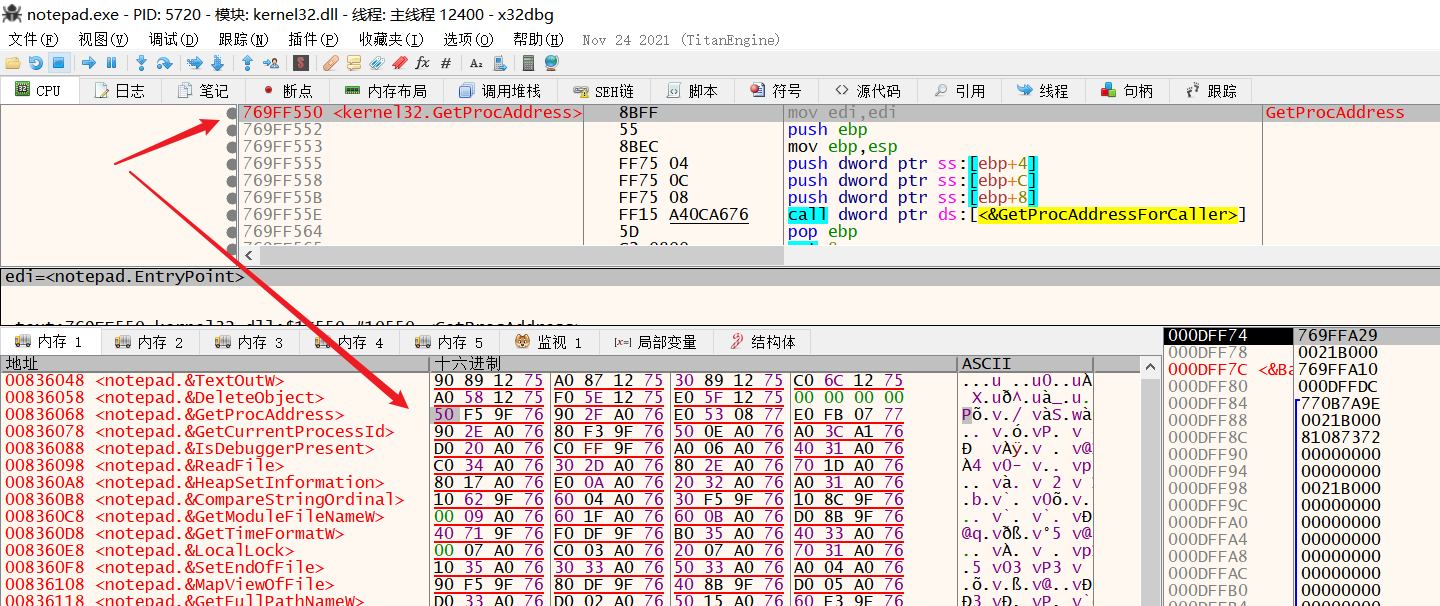
GetProcAddress函数的IAT地址为836068,其值为769FF550,它是API准确的起始地址值。
若在其他OS ( 2000、Vista 等)或服务包(SP1、SP2 )中运行notepad.exe(这个notepad是从win10的syswow64里复制出来的32位notepad),836068地址中会被设置为其他值(相应OS的kernel32.dll的GetProcAddress地址)。
进入769FF550地址中,如上图所示,可以看到该处即为kernel32.dll的GetProcAddress函数的起始位置。
以上是对IAT的基本讲解,都是一些初学者不易理解的概念。反复阅读前面的讲解,并且实际进入相应地址查看学习,将非常有助于对概念的掌握。IAT是Windows逆向分析中的重要概念,一定要熟练把握。后面学习带有变形IAT的PE Patch文件时,会进一步学习IAT相关知识。
自实现代码解析
IAT表分析代码实现:
1 | |
效果截图:
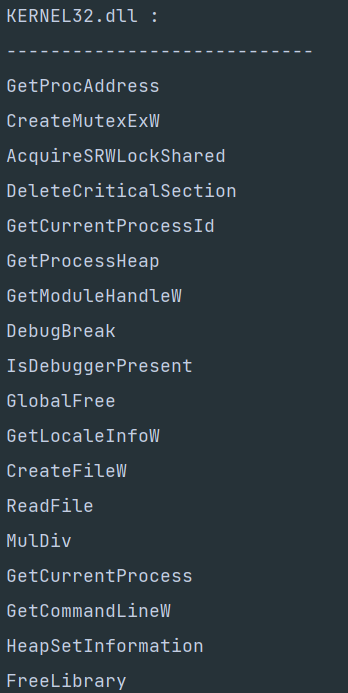
13.6 EAT
Windows操作系统中,“库”是为了方便其他程序调用而集中包含相关函数的文件(DLL/SYS)。Win32 API是最具代表性的库,其中的kernel32.dll文件被称为最核心的库文件。
EAT是一种核心机制,它使不同的应用程序可以调用库文件中提供的函数。也就是说,只有通过EAT才能准确求得从相应库中导岀函数的起始地址。与前面讲解的IAT—样,PE文件内的特定结构体(IMAGE_EXPORT_DIRECTORY)保存着导出信息,且PE文件中仅有一个用来说明库EAT的IMAGE_EXPORT_DIRECTORY结构体。
对比之下,用来说明IAT的IMAGE_IMPORT_DESCRIPTOR结构体以数组形式存在,且拥有多个成员。这样是因为PE文件可以同时导入多个库。而我们的IMAGE_EXPORT_DIRECTORY只能有一个。
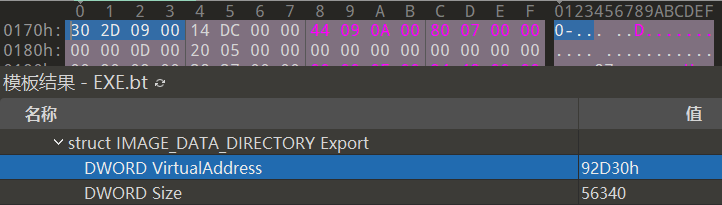
可以在PE文件的PE头中查找到IMAGE_EXPORT_DIRECTORY结构体的位置。IMAGE_OPTIONAL_HEADER32.DataDirectory[0].VirtualAddress 值即是 IMAGE_EXPORT_DIRECTORY结构体数组的起始地址(也是RVA的值)。
下图显示的是kernel32.dll文件的IMAGE_OPTIONAL_HEADER32.DataDirectory[0](第一个4字节为VirtualAddress,第二个4字节为Size成员)
13.6.1 IMAGE_EXPORT_DIRECTORY
IMAGE EXPORT DIRECTORY结构体如下代码所示:
1 | |
下面讲解其中的重要成员(全部地址均为RVA),如下表所示。
| 项目 | 含义 |
|---|---|
| NumberOfFunctions | 实际Export函数的个数 |
| NumberOfNames | Export函数中具名的函数个数 |
| AddressOfFunctions | Export函数地址数组(数组元素个数=NumberOfFunctions) |
| AddressOfNames | 函数名称地址数组(数组元素个数=NumberOfNames) |
| AddressOfNameOrdinals | Ordinal地址数组(数组元素个数=NumberOfNames) |
下图描述了kernel32.dll文件的IMAGE_EXPORT_DIRECTORY结构体与整个EAT结构。
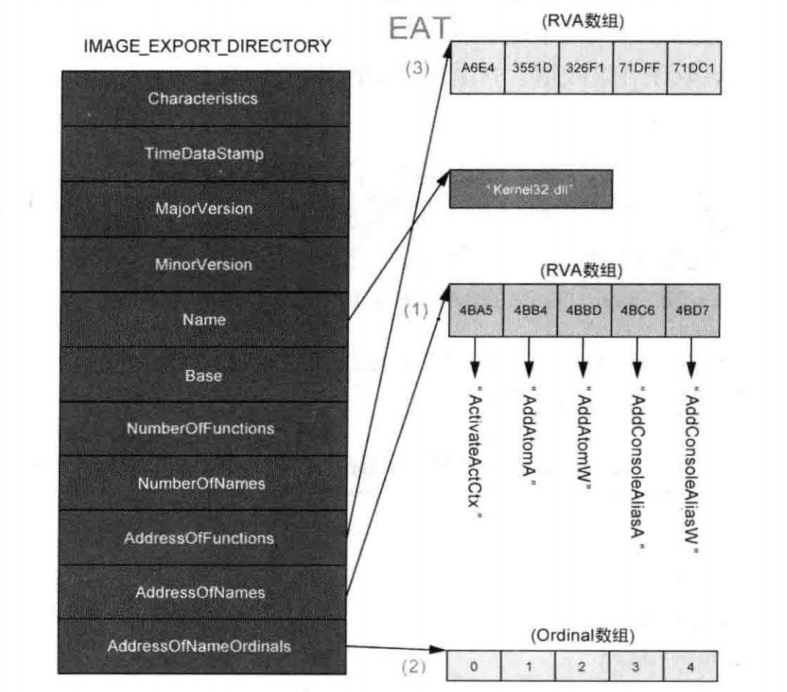
从库中获得函数地址的API为GetProcAddress()函数。该API引用EAT来获取指定API的地址。
GetProcAddress() API拥有函数名称,下面讲解它如何获取函数地址。理解了这一过程,就等于征服了EAT。
GetProcAddress()操作原理
- (1)利用AddressOfNames成员转到“函数名称数组”。
- (2) “函数名称数组”中存储着字符串地址。通过比较(strcmp)字符串,查找指定的函数名称(此时数组的索引称为name_index )。
- (3)利用 AddressOfNameOrdinals 成员,转到ordinal 数组。
- (4)在ordinal数组中通过name_index查找相应ordinal值。
- (5)利用AddressOfFunctions成员转到“函数地址数组”(EAT)。
- (6)在“函数地址数组”中将刚刚求得的ordinal用作数组索引,获得指定函数的起始地址。
上图描述的是kernel32.dll文件的情形。kernel32.dll中所有导岀函数均有相应名称,
AddressOfNameOrdinals数组的值以index=ordinal的形式存在。但并不是所有的DLL文件都如此。
导出函数中也有一些函数没有名称(仅通过ordinal导岀),AddressOfNameOrdinals数组的值为index!=ordinal。所以只有按照上面的顺序才能获得准确的函数地址。
对于没有函数名称的导出函数,可以通过Ordinal查找到它们的地址。从Ordinal值中减去IMAGE_EXPORT_DIRECTORY.Base成员后得到一个值,使用该值作为“函数地址数组”的索引,即可查找到相应函数的地址。
13.6.2 使用 kernel32.dll 练习
下面看看如何实际从kernel32.dll文件的EAT中查找AddAtomW函数并获取其函数地址。kernel32.dll的IMAGE_EXPORT_DIRECTORY结构体RVA为92D30,换算成RAW为78D30。
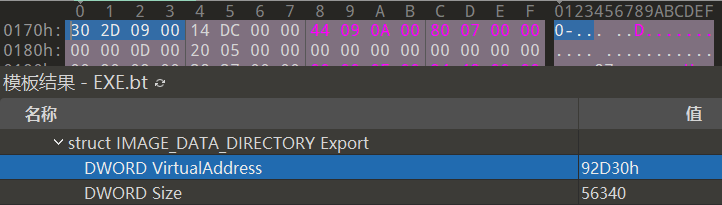
使用010Editor进入78D30偏移处,如下图所示。
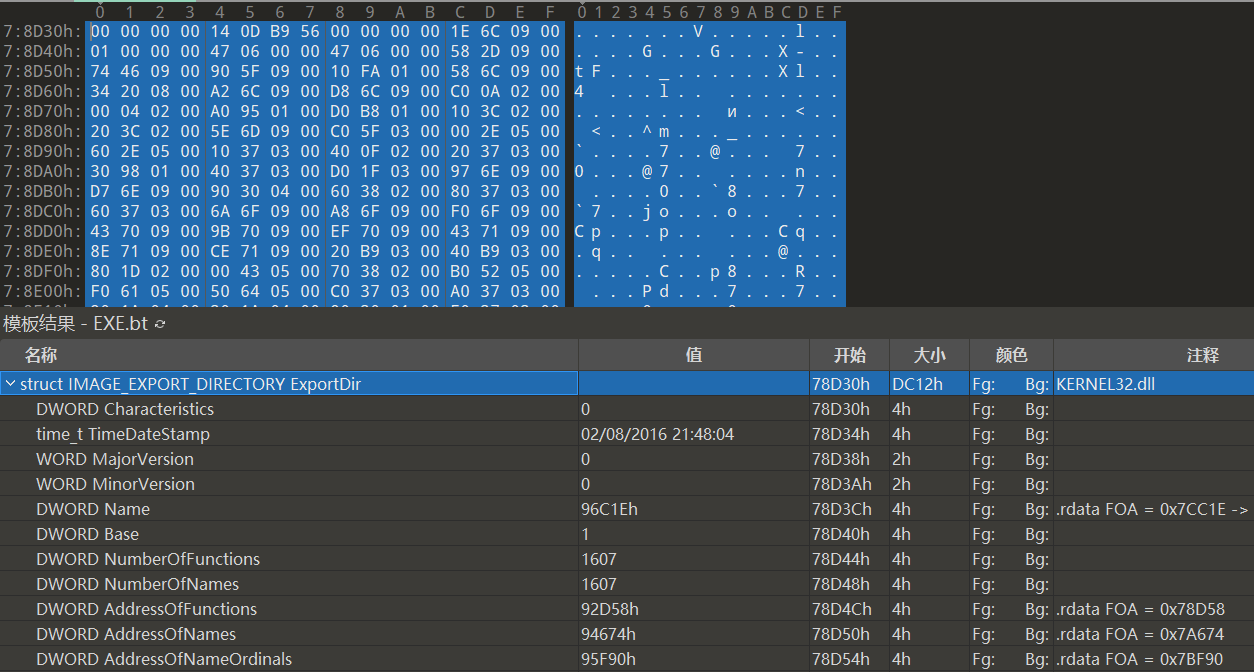
将几个成员的值抽取出来,如下所示:
| 文件偏移 | 成员 | 值 | RAW |
|---|---|---|---|
| 98BE0h | DWORD Characteristics | 0 | - |
| 98BE4h | time_t TimeDateStamp | 02/08/2016 21:48:04 | - |
| 98BE8h | WORD MajorVersion | 0 | - |
| 98BEAh | WORD MinorVersion | 0 | - |
| 98BECh | DWORD Name | 96C1Eh | - |
| 98BF0h | DWORD Base | 1 | - |
| 98BF4h | DWORD NumberOfFunctions | 1607(647h) | - |
| 98BF8h | DWORD NumberOfNames | 1607(647h) | - |
| 98BFCh | DWORD AddressOfFunctions | 92D58h | .rdata FOA = 0x78D58 |
| 98C00h | DWORD AddressOfNames | 94674h | .rdata FOA = 0x7A674 |
| 98C04h | DWORD AddressOfNameOrdinals | 95F90h | .rdata FOA = 0x7BF90 |
下面通过模拟GetProcAddress()获取函数地址的方式对各个字段进行讲解。
- 函数名称数组
AddressOfNames成员的值为RVA=94674,即RAW=7A674。使用010Editor查看该地址,如下图
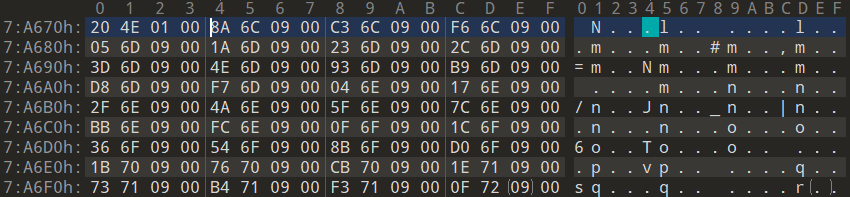
此处为4字节RVA组成的数组。数组元素个数为NumberOfNames ( 647h)。遍历所有RVA值即可发现函数名称字符串。
- 查找指定函数名称
要查找的函数名称字符串为“AddAtomW”,在上图中遍历到第六个元素的值RVA数组的值(RVA:96D23→RAW:7CD23)即可。
进入相应地址就会看到“AddAtomW”字符串,如下图所示。此时“AddAtomW”函数名即是上图数组的第六个元素,数组索引为5。

- Ordinal数组
下面查找 “AddAtomW” 函数的Ordinal值。AddressOfNameOrdinals成员的值为RVA:95F90→RVA:7BF90。
在下图中可以看到,深色部分是由多个2字节的ordinal组成的数组( ordinal数组中的各元素大小为2个字节)。

- ordinal
将2中求得的index值(5)应用到3中的Ordinal数组即可求得Ordinal(8)。
AddressOfNameOrdinals[index]=ordinal
(index=5,ordinal=8)
- 函数地址数组-EAT
最后查找AddAtomW的实际函数地址。AddressOfFunctions成员的值为RVA:92D58→RVA:78D58。 下图深色部分即为4字节函数地址RVA数组,它就是Export函数的地址。
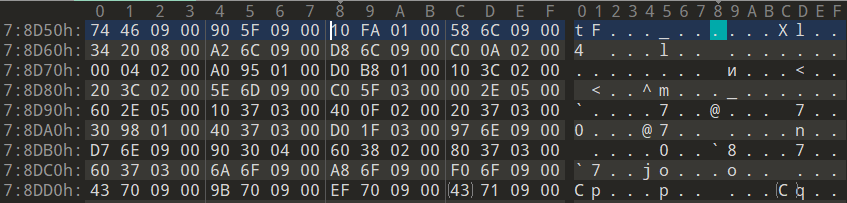
- AddAtomW函数地址
图13-26中,为了获取“AddAtomW”函数的地址,将第4步所求的Ordinal用作上图数组的索引,得到RVA=1B8D0。
AddressOfFunctions[ordinal]=RVA
(ordinal=7,RVA=195A0)
使用x32dbg进行验证,kernel32.dll的ImageBase=7A270000。因此AddAtomW函数的实际地址(VA)为7A2895A0(7A270000+1B8D0=7A28B8D0)。如下图所示:
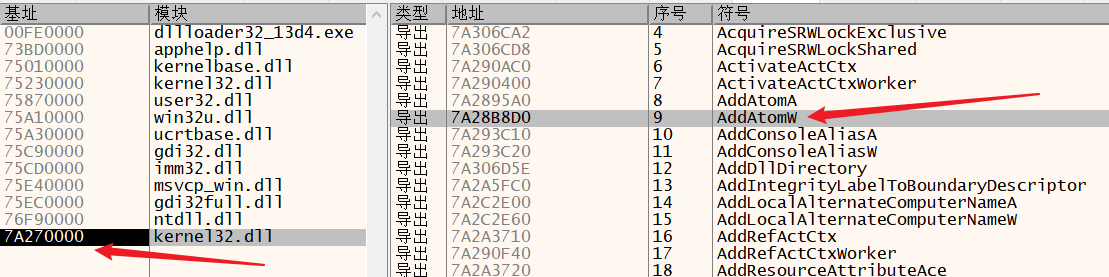
以上过程是在DLL文件中查找Export函数地址的方法,这与使用GetProcAddress() API获取指定函数地址的方法一致。
最基本、最重要的部分到此就全部讲完了。要理解这些内容并不容易,若有不理解的暂且保留,通过实际操作慢慢理解
自实现代码解析
1 | |
13.7 高级PE
前面我们花了相当长时间来学习PE文件格式相关知识。虽然可以根据PE规范逐一学习各结构体成员,但前面的学习中仅抽取与代码逆向分析息息相关的成员进行了说明。其中IAT/EAT相关内容是运行时压缩器(Run-timePacker)、反调试、DLL注入、API钩取等多种中高级逆向主题的基础知识。希望各位多训练使用Hex Editor,铅笔、纸张逐一计算IAT/EAT的地址,再找到文件/内存中的实际地址。虽然要掌握这些内容并不容易,但是由于其在代码逆向分析中占有重要地位,
所以只有掌握它们,才能学到高级逆向技术。
13.7.1 PEView.exe
下面向各位介绍一个简单易用的PE Viewer应用程序(PEView.exe )(个入编写的免费公开SW )。
http://www.magma.ca/~wjr/PEView.zip
下图是PEView.exe的运行界面。
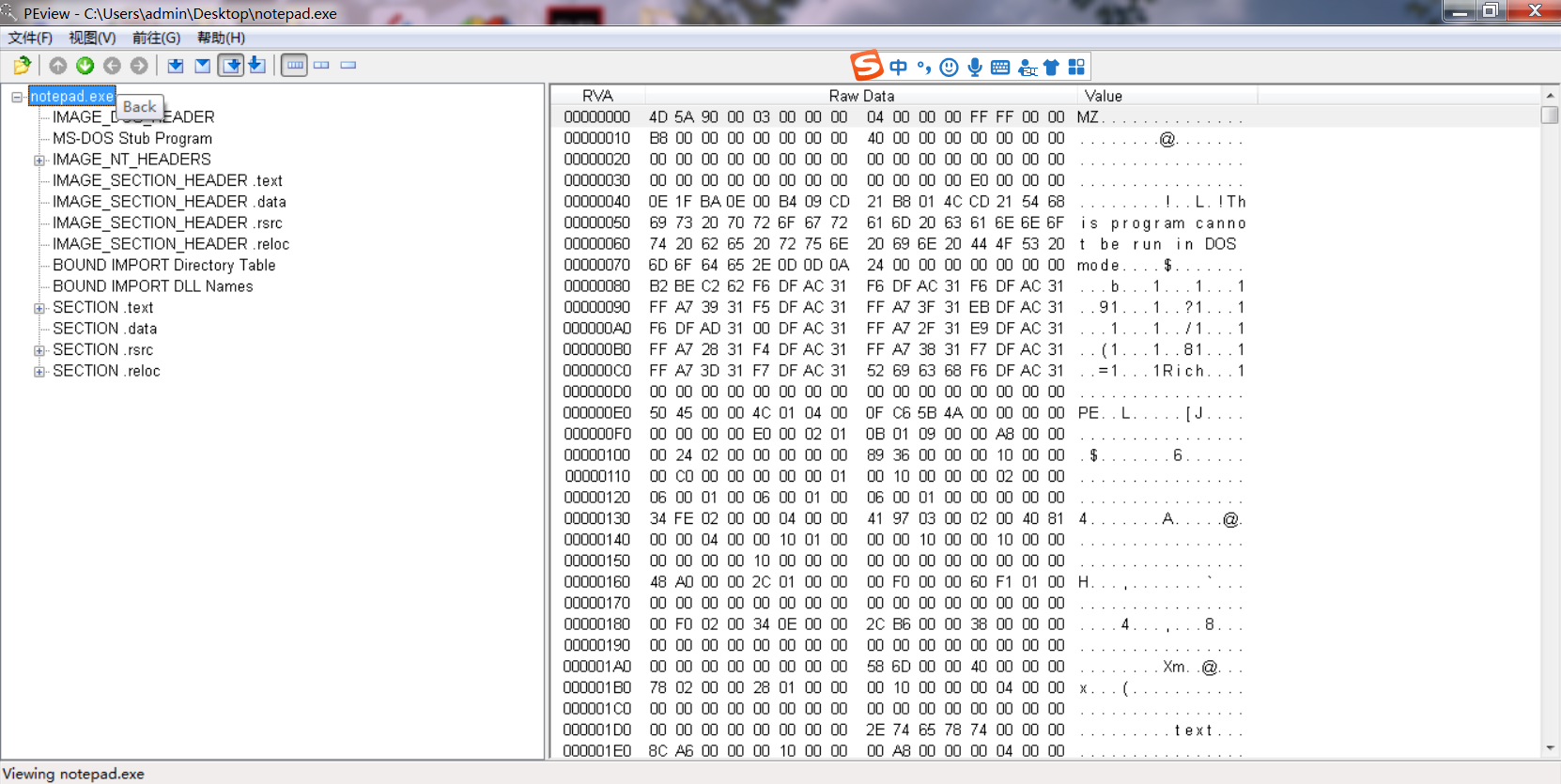
PEView中,PE头按不同结构体分类组织起来,非常方便查看,也能非常容易地在RVA与文
件偏移间转换(与前面讲解的内容与术语略微不同。若二者都能熟练掌握,与他入沟通时会更加顺畅)。
强烈建议各位自己制作一个PE Viewer。我刚开始学习PE头时(为了验证)就制作了一款基于控制台的PE Viewer,使用至今。亲手制作PE Viewer可以学到更多知识,纠正理解上的错误,
更有利于进步。
13.7.2 Patched PE
顾名思义,PE规范只是一个建议性质的书面标准,査看各结构体内部会发现,其实有许多成员并未被使用。事实上,只要文件符合PE规范就是PE文件,利用这一点可以制作出一些脱离常识的PE文件。
Patched PE指的就是这样的PE文件,这些PE文件仍然符合PE规范,但附带的PE头非常具有创意(准确地说,PE头纠缠放置到各处)。代码逆向分析中,Patched PE涉及的内容宽泛而有深度,详细讲解须另立主题。
这里只介绍一点,但是足以颠覆前面对PE头的常规理解(但仍未违反PE规范)
在下列网站制作一个名为“tinype”的最小PE文件。
http://blogs.securiteam.com/index.php/archives/675
它是正常的PE文件,大小只有411个字节。其IMAGE_NT_HEADERS结构体大小只有248个字节,从这一点来看,的确非常小。其他入也不断加入挑战,现在已经出现了304个字节的PE文 件。有入访问上面网站后受到了刺激,制作了一个非常极端、非常荒唐的PE文件,在下列网址中可以看到。
http://www.phreedom.org/solar/code/tinype/
进入网站后可以下载一个97字节的PE文件,它可以在Windows XP中正常运行。并且网站记录了PE头,与tiny pe的制作过程,认真阅读这些内容会有很大帮助(需要具备一点汇编语言的知识)。希望各位全部下载并逐一分析,技术水平必有显著提高。
13.8 小结
这些Patched PE文件能够帮助打破对PE文件的固有概念,对我、对普通的逆向分析入员都一样。正因如此,逆向分析技术学起来才更有意思。关于PE头需要再次强调的内容整理如下。
- PE规范只是一种标准规范而已(有许多内容未使用)。
- 现在已知关于PE头的认识中有些是错误的(除tinype外,会出现更多操作PE头的创意技巧)。
- 经常检验掌握的知识,发现不懂的马上补充学习。
后面还会有机会详细分析、学习Patched PE文件有关知识,到时再向各位一一介绍有关操作PE头更多有趣而奇特的技巧。
Q.前面的讲解中提到,执行文件加载到内存时会根据Imagebase确定地址,那么2个notepad程序同时运行时Imagebase都是10000000,它们会侵占彼此的空间区域,不是这样吗?
A.生成进程(加载到内存)时,OS会单独为它分配4GB大小的虚拟内存。虚拟内存与实际物理内存是不同的。同时运行2个notepad时,各进程分别在自身独有的虚拟内存空间中,
所以它们彼此不会重叠。这是由OS来保障的。因此,即使它们的Imagebase—样也完全没问题。Q.不怎么理解“填充”(padding)这一概念。
A.相信会有很多入想了解PE文件的“填充”这一概念,就当它是为了对齐“基本单位”而添加的“饶头”。“基本单位”这个概念在计算机和日常生活中都常见。
比如,保管大量的橘子时并不是单个保管,而是先把它们分别放入一个个箱子中,然后再放入仓库。这些箱子就是“基本单位”。并且,说橘子数量时也很少说几个橘子,而说 几箱橘子,这样称呼会更方便3橘子箱数增加很多时,就要增加保管仓库的数量。此时不会再说几箱橘子,而是说“几仓库的橘子”。事实上,这样保管橘子便于检索,查找时 只要说出“几号仓库的几号箱子的第几个橘子”即可。也就是说,保存大量数据时成“捆”
保管,整理与检索都会变得更容易。这种“基本单位”的概念也被融入计算机设计,还被应用到内存、硬盘等。各位一定听说过硬盘是用“扇区”这个单位划分的吧?同样,“基本单位(大小)”的概念也应用到了PE文件格式的节区。即使编写的代码(编译为机器语言)大小仅有100d字节,若节区的基本单位为1000d(400h)字节,那么代码节区最小也应该为1000d。其中100个字节区域为代码,其余900个字节区域填充着NULL(0),后者称为NULL填充区域。内存中也使用“基本单位”的概念(其单位的大小比普通文件要略大一些)。那么PE文件中的填充是谁创建的呢?在开发工具(VC++/VB等)中生成PE文件时由指定的编译选项确定。
Q.经常在数字旁边见到字母“h”,它是什么单位?
A.数字旁边的字母“h”是Hex的首字母,表示前面的数字为十六进制数。另外,十进制数用d ( Decimal )、八进制数用o ( Octal )、二进制数用b ( Binary )标识。
Q.如何只用Hex Editor识别出DOS存根、IMAGE_FILE_HEADER等部分呢?
A.根据PE规范,IMAGE_DOS_HEADER的大小为40个字节,DOS存根区域为40〜PE签名区域。紧接在PE签名后的是IMAGE_FILE_HEADER,且该结构体的大小是已知的,所以也可以在Hex Editor中表示出来。也就是说,解析PE规范中定义的结构体及其成员的含义,即可区分出各组成部分(多看几次就熟悉了)。
Q. IMAGE_FILE_HEADER 的 TimeDateStamp 值为0x47918EA2 ,在 PEView 中显示为2008/01/19,05:46:10 UTC,如何才能这样解析出来呢?
A.使用C语言标准库中提供的ctime()函数,即可把4个字节的数字转换为实际的日期字符串。
Q. PE映像是什么?
A. PE映像这一术语是微软创建PE结构时开始使用的。一般是指PE文件运行时加栽到内存中的形态。PE头信息中有一个SizeOflmage项,该项指出了PE映像所占内存的大小。当然,
这个大小与文件的大小不一样。PE文件格式妙处之一就在于,其文件形态与内存形态是不同的。Q.不太明白EP这一概念。
A. EP地址是程序中最早被执行的代码地址。CPU会最先到EP地址处,并从该处开始依次执行指令。
Q.用PEView打开记事本程序(notepad.exe)后,发现各节区的起始地址、大小等与示例中的不同,为什么会这样呢?
A. notepad.exe文件随OS版本的不同而不同(其他所有系统文件也如此)。换言之,不同版本的OS下,系统文件的版本也是不同的。微软可能修改了代码、更改了编译选项,重新编译后再发布。
Q.对图13-9及其下面的Quiz不是很理解。如何知道RVA 5000包含在哪个节区呢?
A.图13-9是以节区头信息为基础绘制的。图(或节区头信息)中的.text节区是指VA 01001000-01009000区域,转换为RVA形式后对应于RVA 1000〜9000区域(即减去Imagebase值的01000000 )。由此可知,RVA 5000包含在.text节区中。
Q.讲解节区头成员VirtualAddress时提到,它是内存中节区头的起始地址(RVA),
VirtualAddress不就是VA吗?为什么要叫RVA呢?A. “使用RVA值来表示节区头的成员VirtualAddress”,这样理解就可以了。节区头结构体
(IMAGE_SECTION_HEADER )的 VirtualAddress成员与虚拟内存地址(VA , VirtualAddress )用的术语相同才引起这一混乱。此处“VirtualAddress成员指的是虚拟内存中相应节区的起始地址,它以RVA的形式保存”,如此理解即可。Q.查看某个文件时,发现其IMAGEJMPORT_DESCRIPTOR结构体的OriginaFirstThunk成员为NULL,跟踪FirstFThunk成员,看到一个实际使用的API的名称字符串数组(INT)。
跟踪FirstThunk应该看到的是IAT而不是INT,这是怎么回事呢?A. PE装载器无法根据OriginalFirstThunk查找到API名称字符串数组(INT)时,就会尝试用FirstThunk查找。本来FirstThunk含义为IAT,但在实际内存中被实际的API函数地址覆盖 掉了(此时INT与IAT虽然是相同区域,但仍然能够正常工作)。
Q.使用Windows7的notepad.exe测试,用PEView打开后,IAT起始地址为01001000,而用OllyDbg查看时IAT出现在00831000地址处。请问这是怎么回事呢?
A.这是由Windows Vista、7中使用的ASLR技术造成的。请参考第41章。
Q. EAT讲解中提到的Ordinal究竟是什么?不太理解。
A.把Ordinal想成导出函数的固有编号就可以了。有时候某些函数对外不会公开函数名,仅公开函数的固有编号(Ordinal)。导入并使用这类函数时,要先用Ordinal查找到相应函数 的地址后再调用。比如下面示例(1)通过函数名称来获取函数地址,示例(2)则使用函数的 Ordinal来取得函数地址。
示例(1) pFunc=GetProcAddress( “TestFunc”);
示例(2) pFunc=GetProcAddress(5);
参考
《逆向工程核心原理》 第13章